A deep learning method for frame selection in videos for structure from motion pipelines
Abstract
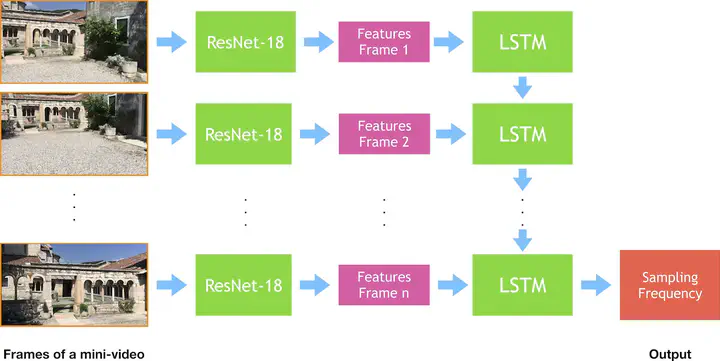
Structure-from-Motion (SfM) using the frames of a video sequence can be a challenging task because there is a lot of redundant information, the computational time increases quadratically with the number of frames, there would be low-quality images (e.g., blurred frames) that can decrease the final quality of the reconstruction, etc. To overcome all these issues, we present a novel deep-learning architecture that is meant for speeding up SfM by selecting frames using predicted sub-sampling frequency. This architecture is general and can learn/distill the knowledge of any algorithm for selecting frames from a video for generating high-quality reconstructions. One key advantage is that we can run our architecture in real-time saving computations while keeping high-quality results.